Why the WIMP User Interface is Dead? (for information retrieval)
TweetUpdated: Nick Carr featured this post in his Sunday Links post. Thanks Nick.
Context: This is a follow-on to my “Thanks to Google – WIMP user interface is dead” post. Please read that post for links to Nick Carr’s original post and rejoinder, Sadagopan’s rejoinder and Ganesh’s and Vinnie’s comments on Nick’s blog. The innovative Ajax Office contender Zoho joined the debate as well – review Sridhar Vembu’s comments and also Arvind Natarajan’s post.
Prologue:
There are 2 main objections that came up which I want to address and also provide some theoretical foundation for my argument: 1. Ganesh’s high context, high semantics argument. His comment on Nick’s blog is more explanatory. He asks how does Onebox service a query “Give me all invoices processed by John Smith and reviewed by John Doe after 08/11/2004”. Short answer: It may not, directly. Long answer: coming up. 2. Sadagopan says (Emphasis provided by Sadagopan):
Enterprise Information architecture is far more complex than what it seems to suggest ( generally speaking enterprise level rollouts are lot more sophisticated than consumer centric rollouts)–
I have sat through/chaired numerous exercises/workshops/walkthroughs of taxanomy development inside large enterprises – several times getting
to accept a common taxonomical structure itself could be elusive. I
know of organizations (which are rated amongst top 3 best knowledge
management organization in the world repeatedly) struggling to even
converge on a common taxanomy framework – they are using three –four different frameworks (all in use simultaneously). The search/synthesis needs of large enterprises using multiple information
repositories are best addressed through better information architecture frameworks and not on any technological standardized bruteforce approaches.
Short answer: Sadagopan is correct. But I am not advocating Search as a panacea. Long answer: Coming up.
Theory:
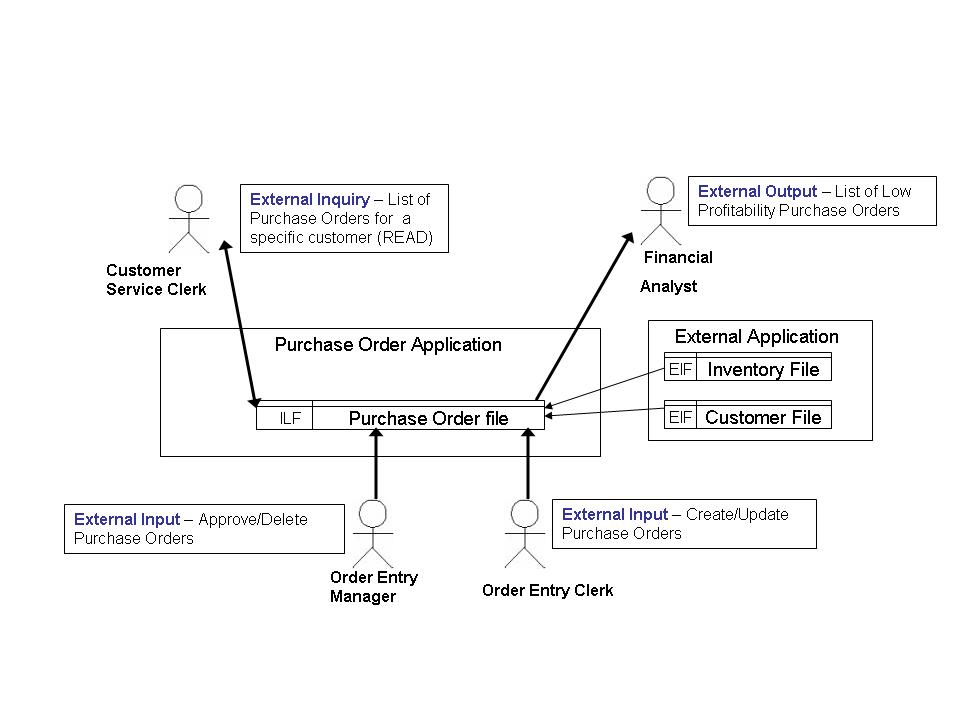
Having used it since 1990, I am a firm believer in the Function Point Analysis (FPA) method of effort estimation invented by IBM’s Allan Albrecht in 1979. While the relevance of FPA may not be entirely obvious, please bear with me, as I explain how I used FPA to develop the theory for this strategy. FPA is quite involved and providing a detailed explanation of it is outside the scope of this discussion. I explain as much is necessary to understand the overall strategy I alluded to in my previous post. Albrecht based FPA on an utterly brilliant revelation that all OLTP applications have a similar structure. You can think of this as a uber-pattern (long before design patterns were made popular by the Gang of Four in the software industry). Let me explain the pattern using the diagram below:

Its a simple Purchase Order application which has 4 functions:
1. create/update purchase orders executed by Order Entry Clerk,
2. approve/delete purchase orders executed by Order Entry Manager,
3. list purchase orders for a specific customer executed by Customer Service Clerk
4. list of low profitability purchase orders executed by Financial Analyst. It stores the information in an internal Purchase Order file and refers external files Inventory File and Customer File.
Per FPA, all OLTP applications have 5 parts to them:
1. External Inputs (EI) – which take information from outside the application and modify the data in the application. These inputs typically come via human operators but does not preclude feeds from other systems. For example, the Create/Update and Approve/Delete purchase orders functions in this sample app.
2. External Outputs (EO) – which applies some amount of complex processing to the information and sends it outside the application. For example, the list low profitability purchase orders in this sample app. You can see that calculating profitability would involve some complexity.
3. External Inquiries (EQ)- which spit out information from inside the application without much processing based on criteria input from the outside. For example, the list purchase orders for a specific customer in this sample app. Here the specific customer name or number is an input and the simple output is a list of purchase orders. I had referred to EQs as the READ part of OLTP applications in my previous post, which I guess created some confusion.
4. Internal Logical Files (ILF)- these are the storehouses of information for the application. For example, the Purchase Order File in this sample app. Additionally, External Inputs, Outputs and Inquiries process/maintain these files.
5. External Interface Files (EIF) – these are storehouses of information that are used by the application but are maintained outside the application. For example, the inventory file and customer file in this sample app. FPA is technology neutral and if you try to correlate this pattern with OLTP applications that you are familiar, you will see how closely this pattern applies.
In my 15 years experience with this tool, I can say that it is uncannily accurate.
Now, onto my main argument – If you look at the External Inquiries (EQ), you can see that these are simple queries on the underlying database which can easily be serviced by SQL. Every OLTP application develops these EQs because these are important to service the basic information needs of the users of the application.
In this sample app, the customer service clerk just wants to know which are the purchase orders that have been raised for a given customer. Now quite obviously, you tend to house these EQs in the same WIMP interface that services all the users of the system and they are forced to navigate the featuritis-plagued WIMP interface that has been designed for the more complex EIs and EOs.
Given that there are a ton of legacy apps, there are still several mainframe applications, whose green screen UIs you have to contend with, as a EQ user with a simple information need. Overall, in the Enterprise context, there is no easy way to get at simple information without having to understand the UIs of the various applications littered around within the Enterprise.
In this situation, if you had a Onebox interface using Search, you can easily imagine the simple purchase order hooked into it and the Customer Service clerk servicing the “list the purchase orders for a given customer” using the Onebox search. Back to Ganesh’s and Sadagopan’s points – I think a lot of fragmentation of taxonomy happens in the Enterprise because all OLTP apps have become silos or islands of information or fiefdoms because the users of these apps have to come to the app for extracting information.
Now if you adopt the Onebox Search metaphor as a unifying approach, i believe that the individual OLTP fiefdoms will be more motivated to adhere to a common taxonomy atleast for EQs. Let’s look at the same purchase order app, you enter “Purchase Order” followed by “Customer Name ” and hit enter and out pops the list of purchase orders.
Now time series is an important retrieval criterion that it ought to be built into all Search Results pages. For example, see how Google’s Blogsearch builds this in. Click on this link. I have added the resulting image below for your convenience. 
If you look at the frame on the left hand side (picture above), you see the whole time series, which can be used to subset the results based on time series easily. Additionally, you can include the key attributes of the Purchase Order or any other Business Entity and use it in an Advanced Search page. This will allow you to also unify the taxonomy and the UI for basic retrieval needs even if you have disparate Purchase Order systems.
The Advanced Search for Purchase Order could include the attributes Approved-by and Created by. That would allow Ganesh to hit the Advanced Search button, input John Doe in Approved-By and John Smith in Created-By fields and hit enter. I hope this explanation helps you see how this Onebox Search method would work inside the Enterprise for simple information needs.
Notes & References:
1. I call this strategy, Function Point View, after the FPA method. Especially, in legacy transformation, I have seen that this approach helps produce a robust transformation strategy for the application, by allowing you to treat the EIs, EOs, EQs using different technologies. The typical approach of rewriting the legacy application in, whatever is the most, modern technology just replicates the same problems that the legacy app had in the new technology world – classic case of old wine in new bottle.
2. I think building a Function Point View for every OLTP application you build is important and it will be in compliance with IEEE 1471 Recommended Practice for Architecture, which recommends the creation of different viewpoints for different stakeholders. Again, I have used this a lot and is very useful to address the concerns of different stakeholders. Function Point View could be an important Viewpoint to develop.
3. Sridhar Vembu points to an interesting SQLone app from Adventnet that hooks together the different databases using SQL. As I said before, EQs can be easily handled using this approach. Adventnet is not the only one in this space. Endeca is another one that has been building some momentum in this space and they call it “Guided Navigation“. IBM has had for a while now, what it calls Information Integrator that solves this problem.
4. Firefox has already implemented this onebox idea in the search plugin. You can add engines for Amazon, Wikpedia and others directly from Firefox and get the results without having to go to the site in question if your needs are simple. For instance, see how I find the “good to great” book in Amazon right from Firefox below: 
5. A brief introduction to FPA. this will give you an orientation to the topic. FPA is quite involved and adds a lot of value. Some people vehemently oppose FPA as well. Please be aware of that.
Technorati Tags: onebox google search, usability, user interface design

{kind=link}
{kind=link}
Sukumar,
Perhaps, it is my fault – I take the word “one box search” literally and all my past comments (and this one too) is based on that. And anytime I hear any kind of thing becoming dead in the S/W industry, it always seems to come back in a different shape or form.
1. I almost agree that “all OLTP apps have become silos or islands of information or fiefdoms“. I would just change “all” to “almost all”. I believe that with the evolution of SOA and mashups, end-users will have the ability to develop sit-apps by putting together services created by IT organizations. This would be one way to destruct the silos – exposing capabilities as services. UIs can be put together by end-users based on the services.
2. In the example, the minute I have to press the “Advanced Search” button, it is not “one button search” anymore!! In the blogsearch example you gave, I certainly would not want to remember the syntax for the search string – “inblogtitle:PSFK inpostauthor:Sukumar blogurl:http://www.psfk.com/“. So, I would end up using the “Advanced Search” button. And I would certainly like a pointer device (mouse in this case) to navigate the text boxes in the “Advanced Search” window. I as software professional would not want to remember the syntax. So, in your example, I would certainly not expect the Order Entry Clerk or Financial Analyst remember the syntax for his/her search. I do agree that for _very basic_ searches, one-box could be the way to go.
3. I do not understand the relevance of “one-box” search with solutions such as IBM’s “Information Integrator”. This like lots of their software is a middleware that lets one aggregate/integrate data (both structured and unstructured) across multiple-disparate repositories. It provides a way to unify data and let a single search gather data from the various repositories. The UI/veneer for these searches could be anything – one-box or not.
Ganesh
Ganesh,
Thanks for the comments.
1. Yes, you are right in the sense that WIMP will not die that easily and it should not because it does offer significant productivity improvements.
2. I am only arguing that Search could be a unifying metaphor for the various app silos in the Enterprise. Its not necessary that it has to be one button. Therefore, when you use Onebox search, you can do simple searches and using Advanced Search you can do slightly more advanced searches. The search string I used in my PSFK example was generated using Google’s advanced search page, i didnt have to remember it.
3. I was talking about IBM’s Information Integrator in the context of Adventnet SQLOne type of approoach. It allows you to create a federated query that runs across several information stores and bring back the information.
Interesting debate again.